

Serverless Inference Providers Compared [2026]

TL;DR
We compared the most popular serverless inference services (Modal, Replicate, RunPod, beam.cloud, and dat1.co) using the Qwen Image model on a single Nvidia H100.
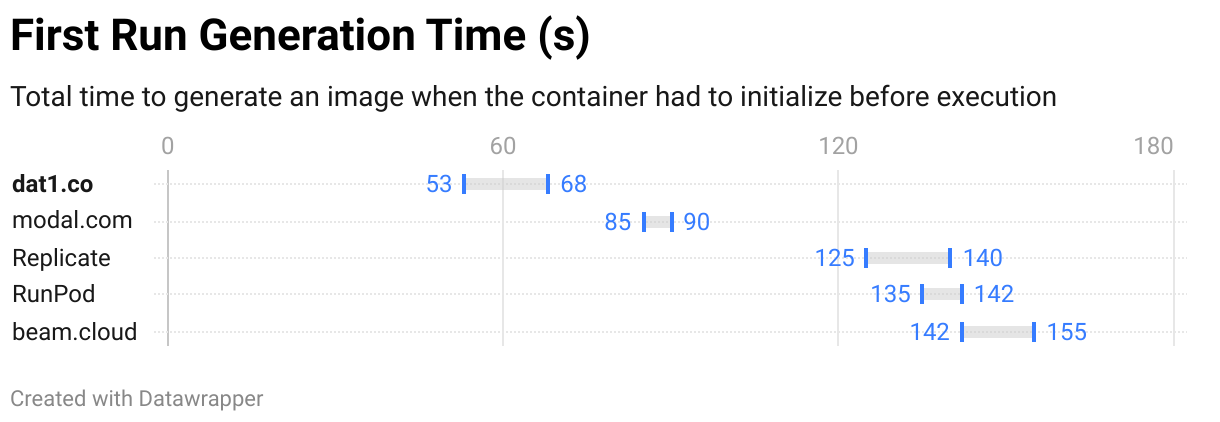
First run or cold start happens when you make a request on either a cold container or when your endpoint scales up. You can see the overhead that initialization has on the total request time. The actual generation takes 30-40s in all of our tests.
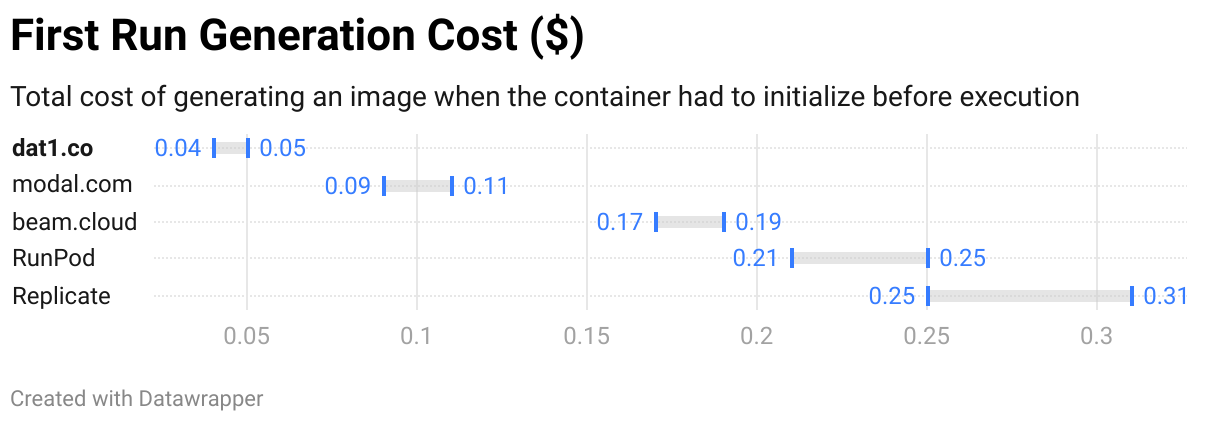
Another important aspect is the convoluted pricing structure of different services. This graph shows exact price to generate an image, including all charges for the start and timeout times. Please note that some services also charge for storage and each deployment, this is not included in this test.
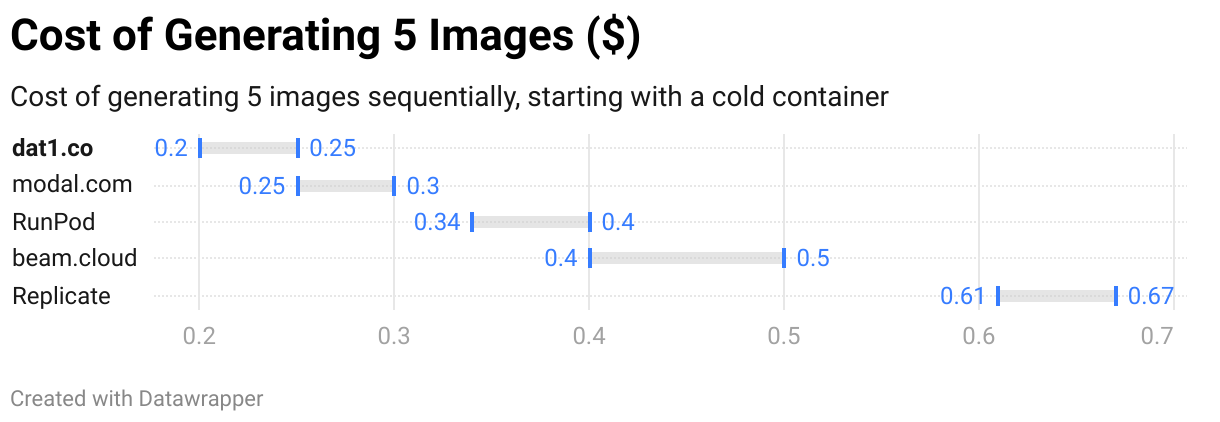
We also tested a simple scenario to show how costs scale when running subsequent generations after the first start. The generation time (excluding the first request) is the same across all the services.
Cold Start
One of the drawbacks of going serverless is the cold start. Essentially, all serverless technologies will introduce additional delay in response time when a certain endpoint is hit for the first time in a while or when scaling up. This is even more important with machine learning workloads as they usually have to download and load a big model into memory.
To make this more pronounced, we used a model that takes ~56 GB of VRAM when loaded: Qwen Image fp16.
The generation itself takes around 30-40 s across all of our tests (done with the same prompt and input parameters). Most of the services add 3-4x that time to spin up a container.
There are a lot of factors that affect the cold start time. As an example, the open-source gpt-oss-120b model that requires ~65 GB of VRAM has a much lower cold start of ~12 seconds on dat1.
One of the significant factors that increases cold starts with other platforms is the usage of custom docker images. Allowing only one base image with pre-baked dependencies is one of the core decisions that allow dat1.co to have significantly lower cold starts. This, of course, has a drawback: it makes it harder to customize workflows and adapt models to our platform.
Pricing & Costs
It's not that easy to understand exact costs from just looking at the pricing page. While the per-GPU-second price is usually visible, the total cost is not always clear: there might be separate charges for the CPU and RAM, charges for the startup and idle time, sometimes even charges for each new version deployed.
We tested two scenarios:
-
Generating one image without running container to highlight the hidden costs of starting and idling a container.
-
Generating five images consecutively to show how the costs scale with more requests.
When choosing a platform, it's important to understand the pricing structure, and sometimes there's no easier way of learning it than by running a proof-of-concept. At dat1.co, we strive to make pricing as predictable as possible.
Methodology
As mentioned earlier, we used the same model (Qwen Image fp16), same hardware (a single NVIDIA H100), and the same prompt and generation settings on all platforms.
In each test, we used a modest sample size of 10 runs.
While there might be some valid bias in us comparing our own platform to others, we tried following the best practices outlined in each platform's documentation to make the test as neutral as possible. Source code of the handlers and models used is available here.
Limitations
There are, of course, important aspects that we did not test within the scope of this article: scaling mechanisms, deployment complexity, support availability, uptime, GPU availability.
Since the tests were done on a single model, it’s important to note that cold start depends not only on model size but also on the initialization code. Also, we do not recommend extrapolating these results to other GPU types.
AWS SageMarker Serverless is not included in this test as it does not support GPU instances[1].
Last updated: 01.15.2026
Links
1 - https://docs.aws.amazon.com/sagemaker/latest/dg/serverless-endpoints.html
Comments