

LLM Quantization Comparison
Quantization is a critical technique for deploying large language models efficiently, reducing memory footprint and improving inference speed. However, lower precision often leads to a trade-off in model quality. In this article, we compare various degrees of quantization, analyzing their impact on both speed and output quality.
Performance Comparison
The table below presents a performance comparison of different quantization levels applied to the DeepSeek-R1-Abliterated model. The models were evaluated across various tasks. LiveBench evaluates model performance across 17 tasks grouped into 6 categories. Let's look at these categories one by one.
Coding
Code generation and a novel code completion task from Leetcode/AtCoder (LiveCodeBench).
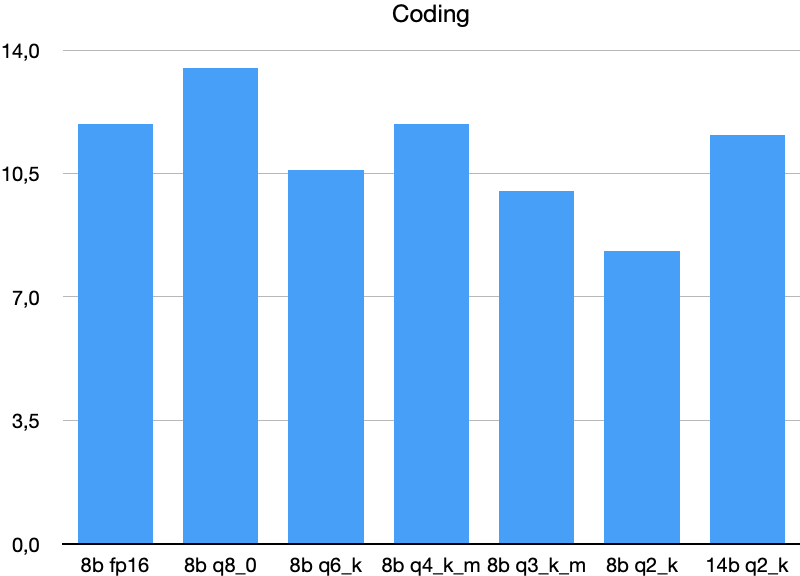
Lower-bit quantization (Q3_K_M, Q2_K) significantly reduces scores.
Data Analysis
Tasks using recent Kaggle/Socrata datasets, including table reformatting, column join prediction, and type annotation.
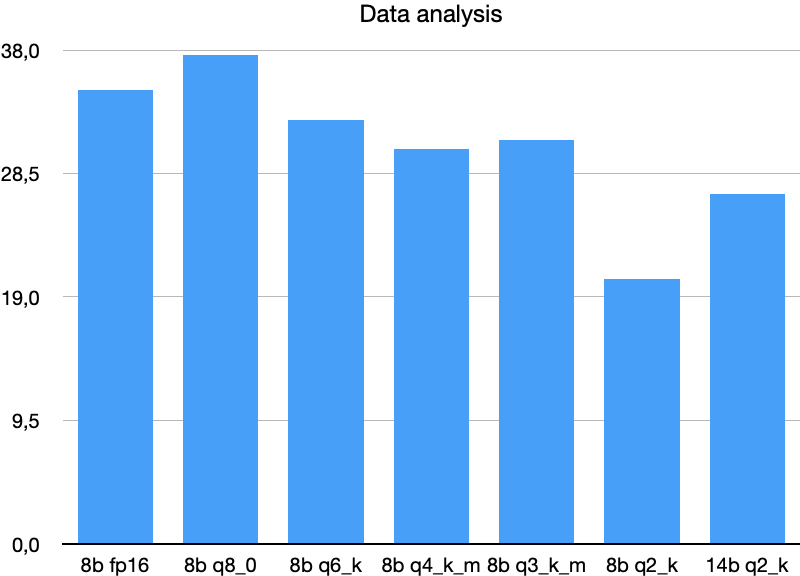
Quantization impacts data analysis tasks similarly to coding.
Instruction Following
Paraphrasing, summarizing, and storytelling based on recent news articles, following specific constraints.
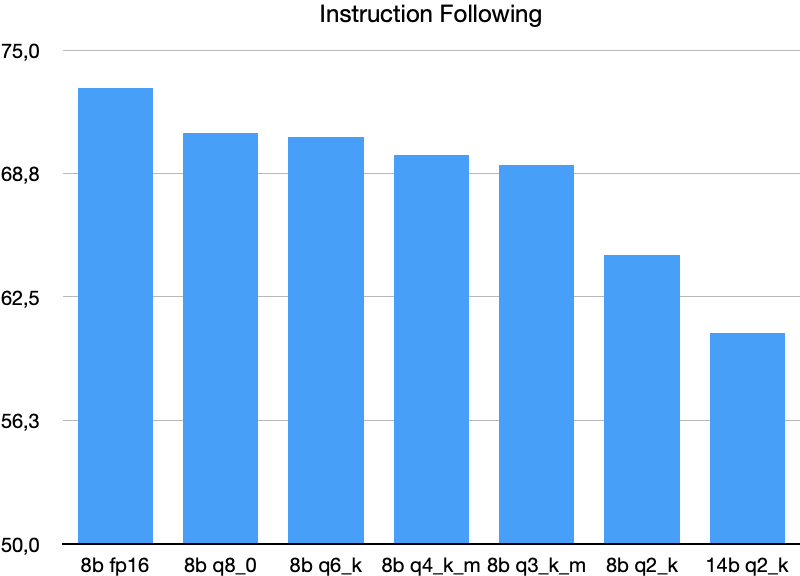
Attention, the graph is cut off at the value of 50!
Quantization slightly reduces performance. Unlike coding and data analysis, the 14B Q2_K model performs worse, which is quite interesting. But more tests needed to draw any conclusions from this.
Language
Word puzzles (Connections), typo correction, and movie synopsis unscrambling.

In this case, the performance of the 14B Q2_K model is the same as that of the 8b 6bit. But, as we will see later, there is little sense in thisу, since the 14b q2 model is significantly inferior in speed with an equal memory footprint.
Math
High school competition problems (AMC12, AIME, USAMO, IMO, SMC) and harder AMPS questions.

Moderate quantization (Q6_K, Q4_K_M, Q3_K_M) maintains similar performance. 14B Q2_K does not show significant improvements relative to the smaller model with less aggressive quantization.
Reasoning
Advanced logic puzzles, including a harder Web of Lies task and Zebra Puzzles.

Surprising. 14B Q2_K model vastly outperforms all 8B variants, suggesting that larger models handle heavy quantization better in complex logical reasoning.
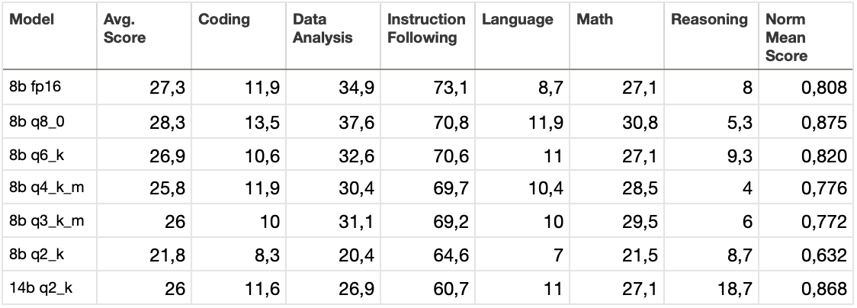
Here is a summary table for all tests:
Additionally, we compare their inference speed across different hardware configurations. Below are the performance comparison tests on different devices. The equipment used for the tests: Nvidia RTX 3090, NVIDIA A100-SXM4-40GB, MacBook Pro 14 with M2 Pro and 32 GB RAM.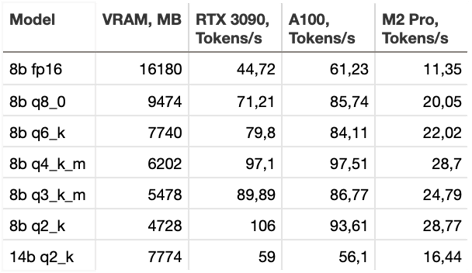
Conclusions
Based on the results of these tests, several obvious conclusions can be drawn:
- Running models in 16-bit precision makes little sense, as a larger, quantized model can deliver better results.
- The 4-bit quantization format is the most popular and offers a good balance, but adding a few extra bits can slightly improve accuracy if sufficient memory is available.
- The larger the model, the greater the advantage of server-grade GPUs with fast HBM memory over consumer-grade GPUs.
- 14b q2_k model requires the same amount of memory as 8b q6_k, but works much slower. At the same time, in all tests except Reasoning, it shows comparable results or even slightly worse. However, these finding should not be extrapolated to larger models without additional testing.
Quantization plays a crucial role in optimizing large language models for deployment. While lower-bit quantization significantly boosts inference speed and reduces memory requirements, it comes with trade-offs in accuracy.
Comments